Zorgdromen




The title of this blog contains two abbreviations, but important ones. IAH is impaired awareness of hypoglycaemia, and AGRP (or AgRP) is agouti-related protein. They are central in a paper just published by my talented colleague, Dr. Rita Varkevisser.

Learn how she summarizes the importance of this paper:
A compelling finding of this study was the association between agouti-related protein (AgRP) and impaired awareness of hypoglycaemia. AgRP is an important neuropeptide in energy homeostasis and is expressed in the adrenal gland and hypothalamus, specifically in the arcuate nucleus (ARC) and ventral hypothalamic nucleus (VMH) where central glucose sensing occurs. These glucose-sensing neurons in the ARC can influence glucose homeostasis through the activation of the autonomic nervous system and exert orexigenic effects through release of AgRP which inhibits MC4R neurons that stimulates food intake. The lower circulating plasma AgRP in individuals with IAH could suggest that these individuals could be less responsive to lower glucose levels. This may be due to threshold changes in the glucose-sensing neurons in the ARC and less hypothalamic-pituitary-adrenal (HPA) activation leading to less AgRP release from neuroendocrine cells in the adrenal medulla.
Another mechanism that may reduce AgRP release is the inhibition by other hormones such as insulin and leptin. Higher circulating levels of insulin usually leads to a reduction in appetite. In some individuals, hypothalamic insulin resistance may lead to increased food consumption despite higher circulating insulin levels. As a consequence of this insulin resistance, these individuals may be protected from hypoglycaemia, as the appetite suppression that would normally occur is no longer present. Although it is not yet clear how recurrent hypoglycaemia can influence glucose sensing and ARC/VMH mediated counterregulatory responses, further research into AgRP may help to elucidate the pathophysiology of IAH.
The mechanisms which dr. Varkevisser summarizers to play a role in IAH, are shown in this figure:
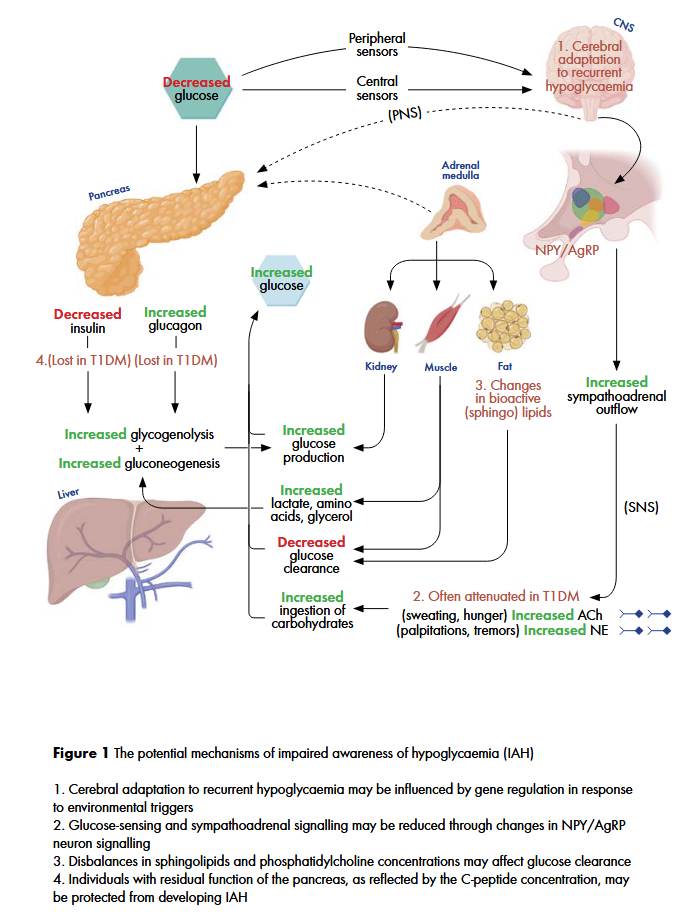
Dr. Varkevisser successfully defended her scientific thesis in November 2024. The full thesis with all her articles can be found on the University of Groningen website: https://research.rug.nl/en/publications/a-balancing-act-navigating-cardiovascular-vigilance-and-hypoglyca
John Mulder, CEO of Diagnoptics: “Mid September, a Dutch national newspaper devoted a full-page article to biological age and AGEs. It’s striking to see how a topic that once lived only in research papers and specialist discussions is now reaching a much wider audience.
Public awareness of biological age is clearly growing, not only among scientists and clinicians, but also within society at large. This raises an important question for all of us in the medical field: how do we translate this momentum into clinical practice?
AGEs remain underexplored in everyday healthcare. Yet early findings already suggest they can add value in prevention, patient engagement, and even perioperative decision-making. For me, this underscores the importance of bridging science and practice, ensuring that what we measure can truly drive better care.
Bron: LinkedIn


Bron: https://viewer.joomag.com/interne-geneeskunde-maastricht-mumc/0683590001462108118/p146

In 1974 werd de Nederlandse Vereniging voor Diabetes Onderzoek (NVDO) opgericht. De oprichtingsvergadering vond plaats op 16 november 1974, zo’n 51 jaar geleden, in het Beatrixgebouw te Utrecht. Het programma van deze feestelijke eerste vergadering staat hierboven.
De NVDO (www.nvdo.online) is een multidisciplinaire vereniging van (basale) wetenschappers, artsen (kinderartsen, internisten, huisartsen), en medisch psychologen die onderzoek doen naar het ziektebeeld diabetes mellitus of een speciale affiniteit hebben met diabetes mellitus.
Het doel van de NVDO is het bevorderen van wetenschappelijk onderzoek op het gebied van het ziektebeeld diabetes mellitus en de toepassing van hierbij verkregen resultaten in de klinische praktijk. Daarnaast wordt uitwisseling van kennis en expertise tussen leden die werkzaam zijn binnen de verschillende disciplines van diabetes mellitus onderzoek gefaciliteerd.
Het eerste bestuur bestond uit onderzoekers en clinici, die in die periode (midden jaren ’70 van de vorige eeuw) actief waren in de zorg voor en begeleiding van mensen met diabetes:
Paul R. Bouman, Groningen (voorzitter)
Janke Terpstra, Leiden (secretaris)
Frits Gerritzen, Wassenaar (penningmeester)
Wepco Reitsma, Groningen (vice-voorzitter)
Ab van ’t Laar, Nijmegen (lid)
In januari 1975 werden door de voorzitter en de secretaris via een officiëel ‘request’ de statuten van de vereniging ter goedkeuring voorgelegd (figuur 2) aan Hare Majesteit de Koningin, Koningin Juliana.

Twee van de oprichters leven dóór in de vereniging, via een specifieke prijs (bron: https://www.nvdo.online/awards/).
Dr. Gerritzen via een prijs die naar zijn vader is vernoemd:
De dr. F. Gerritzen-prijs is een initiatief van Sanofi en wordt jaarlijks toegekend aan een recent gepromoveerde onderzoeker die klinisch onderzoek heeft gedaan op het gebied van diabetes mellitus. De prijs bestaat uit de bronzen dr. F. Gerritzen-penning, een oorkonde en vijfduizend euro voor de winnaar en vijfhonderd euro voor de overige genomineerden. De uitreiking vindt plaats tijdens de wetenschappelijke vergadering voor Diabetes Onderzoek (NVDO).
Daarnaast bestaat de prof.dr.J.Terpstra Award.
De hoofddoelstelling van deze prijs is het stimuleren van jonge onderzoekers die onderzoek verrichten op het gebied van diabetes mellitus. Het winnende voorstel moet een briljant innovatief onderzoeksvoorstel zijn dat een heldere hypothese kent en zal leiden tot resultaten die relevant zijn voor -en toepasbaar voor – mensen met (een hoog risico op) diabetes mellitus. Een begroting op hoofdlijnen moet deel uitmaken van dit voorstel. De Prof. dr. J. Terpstra Young Investigator Award bedraagt 10.000,- Euro. Dit bedrag dient volledig te worden besteed aan het onderzoek zoals dat in het ingediende voorstel is beschreven. De Prof. dr. J. Terpstra Young Investigator Award wordt mogelijk gemaakt door het Diabetes Fonds.

In november 1999 vond ter gelegenheid van het 25-jarig bestaan van de NVDO, de Nederlandse Vereniging voor Diabetes Onderzoek, een fantastisch symposium plaats. Onderaan deze post vindt u een pdf van het jubileum boekje.
In dit jubileum boekje o.a. informatie over de stichting van de NVDO, doelstelling, oprichtingsakte, en het programma van de oprichtingsvergadering op 16 november 1974 in Utrecht, naast natuurlijk de samenvattingen van de voordrachten van de sprekers van die dag.
Het jubileum symposium van 1999 kende een bijzondere opzet. Er was -zoals in de inleiding valt te lezen- voor gekozen om sleutelpersonen uit de academische klinieken een voordracht te laten houden, waarin een overzicht werd gegeven van de belangrijkste vorderingen binnen het wetenschappelijk onderzoek en de diabeteszorg, waaraan door de betreffende universiteit was bijgedragen. Het NVDO bestuur hoopte daarmee de profilering van het Nederlandse wetenschappelijk onderzoek, dat vaak van een zeer hoog gehalte was en nog steeds is, verder te stimuleren. Daarnaast was men er in geslaagd om 2 uitmuntende buitenlandse onderzoekers naar Nederland te halen, Kristian Hanssen en Fran Kaiser, die vanuit hun eigen expertise en wetenschappelijke inspanningen de belangrijkste vorderingen op het gebied van diabetes onderzoek hebben toegelicht.
Het programma was als volgt:
Rotterdam – Diabetes onderzoek in Rotterdam
Dr. H.J. Aanstoot
Amsterdam – VU – Diabetes- epidemiologie: richting gevend voor het fundamenteel onderzoek en het zorgbeleid.
Prof. Dr. R.J. Heine
Groningen – Pancreas- en eilandjestransplantatie
Prof. Dr. R. van Schilfgaarde
Nijmegen – Heparan sulfate alterations in diabetic nephropathy
Dr.J. Berden
Utrecht – Cerebrale dysfunctie in diabetes mellitus
Prof. Dr. W.H. Gispen
Maastricht – The relationship between hyperglycaemia and cardiovascular disease – pathophysiology and pharmacologic intervention
Dr. B. H. R. Wolffenbuttel
Leiden – De groeiende complexiteit van insulineresistentie en type 2 diabetes mellitus
Mw. Dr. D.M. Ouwens
Amsterdam – AMC – Diabeteseducatie: wiens zorg en verantwoordelijkheid?
Dr. R.J. Michels
Oslo, Norway – A long term perspective on the Oslo Study – relationship to biochemical markers of complications
Prof. Dr. K.R Hanssen
Irving, Texas, USA – Erectile dysfunction
Dr. F.E. Kaiser
Het was een gedenkwaardig en zeer succesvol symposium !!!
Download HIER het jubileumboekje.

![]()


Recente reacties